Sound Decisions: Data Scraping and Cleaning 🎧

Lately, I’ve been on the hunt for a new pair of headphones. Instead of spending countless hours searching online for the best pair, I decided to put my data science skills to good use!
To begin, I scraped data from Amazon to create a dataset of headphone products that I could analyse to find the perfect pair.
In this blog post, I’ll share how I tackled web scraping, discuss why it’s such a valuable tool and explain the steps I took to clean the data. This will be the first post in a series where I’ll be sharing my journey in finding the perfect headphones.
Web Scraping
Web scraping is a method used to automatically collect or ‘scrape’ data from websites. It involves writing scripts to extract specific information from websites allowing users to create custom dataset tailored to their needs.
While I’ve used many datasets from Kaggle to build my portfolio, I have come to recognise the importance of collecting my own data. Not only does it offer greater flexibility for projects, like this one, but it also has been a great way to get hands-on experience with real-world data!
How To Web Scrape
Step 1: Assess Robots.txt
The first step in web scraping is to assess the robots.txt file of the website you plan to scrape from. This file outlines the permissions for what can and cannot be scraped, helping you avoid any violations.
To access the robots.txt file, simply go to the base URL of the website and append /robots.txt, like this:

After reviewing the file for Amazon, scraping individual customer reviews was not allowed. This slightly changed the scope of my project since I initially was planning to carry out sentiment analysis on those reviews.
Step 2: Define Base URL
Next, navigate to the specific URL to scrape from. For this project, I focused on the search results for ‘adult headphones’.

https://www.amazon.co.uk/ URL of home page
s?keywords=adult+headphones: Search results for ‘adult headphones’
i = electronics: Searching within the ‘Electronics’ category.
page= Amazon displays a large number of results and not all of them appear on a single page. To handle this, I add page= to the URL, which I will specify later when scraping.
Step 3: Scrape!
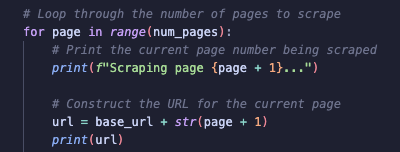
To begin, I loop through the pages until I reach a predefined limit, which I set using the variable num_pages. For each page, I append the current page number to the base URL. This allows me to construct the URL for each specific page I want to scrape. I also included print statements to track the progress of the scraping.
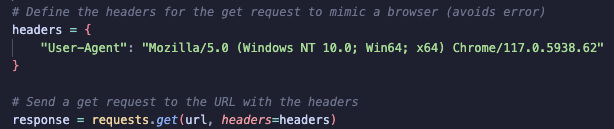
I then define headers to mimic a request from a web browser. Without these headers, Amazon’s server may block the request, as it can detect automated scraping attempts.
If the request is successful, begin reading the content using the BeautifulSoup package. This library allows you to navigate and extract data from the page’s HTML.

To scrape on the products returned by the search, you need to specify which HTML elements BeautifulSoup should read. This requires inspecting the webpage to identify the elements that hold product information.
For example, by using Inspect Element, I found the div containing the search results:
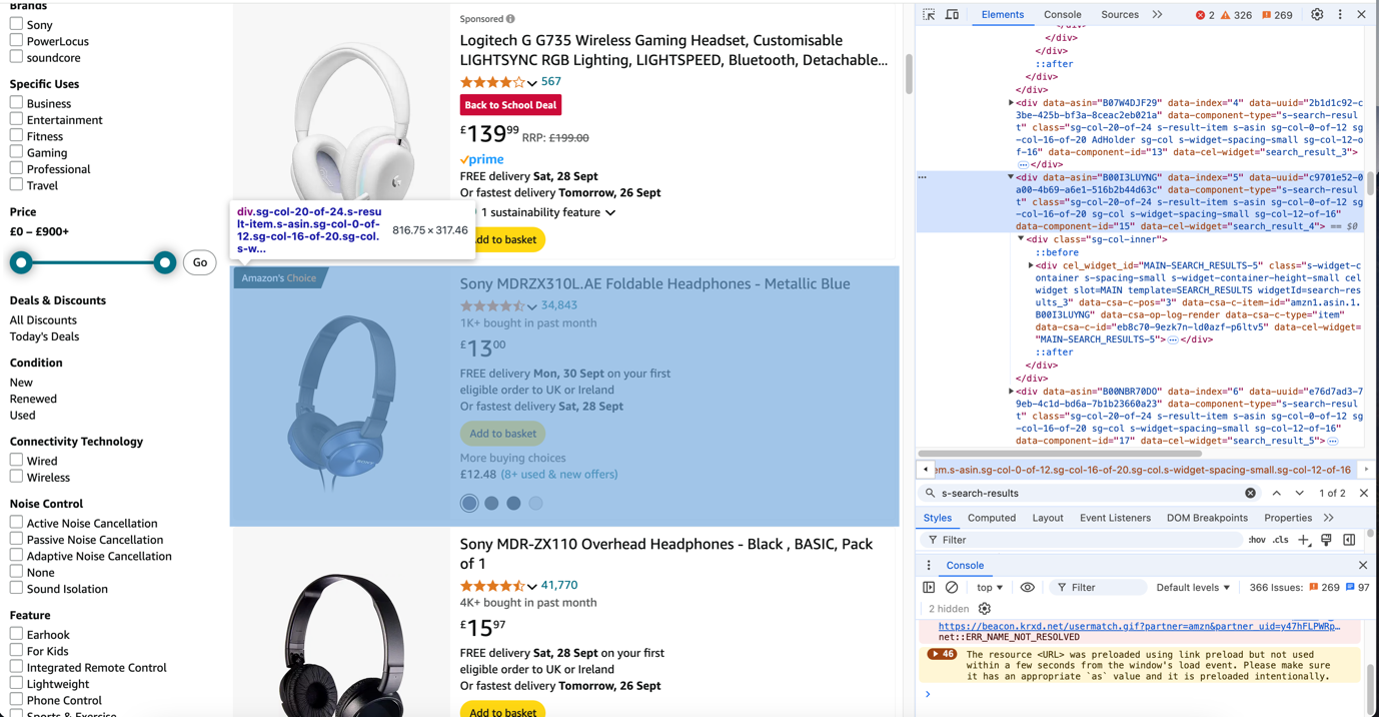

Next, I use .findall from BeautifulSoup to find all div elements with a data-component-type attribute that identifies them as search result items. This is where all the product information is stored.

The following code loops through each headphone in all_headphones and extracts the following:
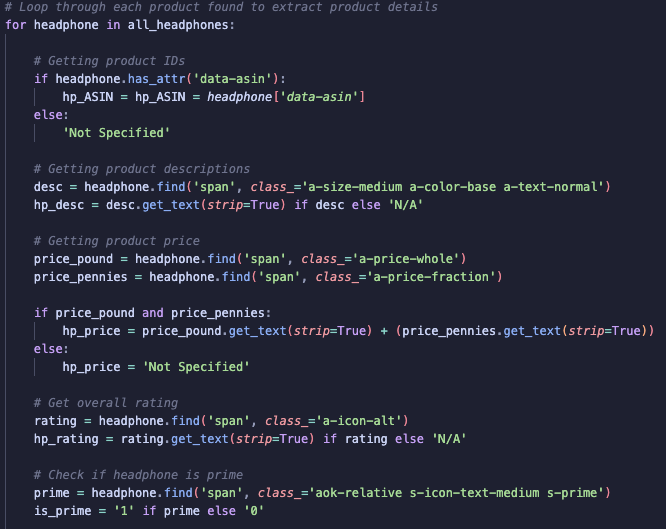
To gather the HTML elements for the information I wanted to extract, I again used Inspect Element. By right-clicking on specific items like product descriptions, prices and ratings, I identified the relevant HTML tags and classes.
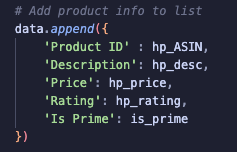
Step 4: Store the scraped data
I used a dictionary to store all the information I wanted in my dataset:
Step 5: Time delay
When scraping data, it’s best practice to introduce a time delay between each request (in this case, after each page) to avoid overloading the server. This delay also helps the web scraping script mimic more human behaviour—such as taking time to browse.

Step 6: Exporting results to CSV
Once done, I create a dataframe using the dictionary I created and export this dataframe to a CSV ready for cleaning.
Data Cleaning
Once data has been scraped from a website like Amazon, the raw data is often messy and requires cleaning before any analysis to ensure insights are accurate and reliable.
First, I checked for missing values and duplicates in the dataset. I removed any duplicates and incomplete rows to ensure a complete dataset.
After the pre-liminary cleaning I decided it best to try and extract as much information as possible from the product description.
Feature Engineering using Product Description
Feature Engineering is the process of creating new columns from data already present in the dataset.
For the following features, I used regular expressions to extract specific features from the product descriptions:
Wireless
I searched the product description for the term ‘wireless’ and created a binary column to indicate whether the product was wireless or not.
Noise Cancelling
Similarly, I searched for the term ‘noise cancelling’ in the description to identify whether this feature was present.
Colour
Extracted colour information from the description using a list of common colours.
Battery Life
Extracted battery life in hours using regular expressions to find numerical values associated with time.
Microphone
Looked for terms like ‘mic’ or ‘microphone’ to identify if the product had a microphone.
Over Ear
Identified ‘over-ear’ products based on related keywords in the description.
Foldable
Flagged products as foldable based on terms like ‘foldable’.
Brand
I also tried to extract the brand names from the product descriptions using SpaCy, a NLP library. However, most brand names in the dataset were either unrecognised or incorrectly identified as common words like ‘wireless’ or ‘bluetooth’. As a result, I thought it best to exclude the product brand from the dataset as the results did not seem too useful.
For examples of the regular expressions used for feature extraction and details on SpaCy implementation, please refer to the project repository (link to be provided once project is complete).
Data Dictionary
| Column | Description |
|---|---|
| Product ID | Product ASIN code |
| Description | Product description |
| Price | Product price |
| Rating | Product rating on a scale of 1 to 5 |
| Is Prime | Binary field showing prime eligibility |
| Wireless | Binary field indicating if product is wireless |
| Noise Cancelling | Binary field indicating if product is noise cancelling |
| Colour | Product colour |
| Battery Life | Product battery life in hours |
| Microphone | Binary field indicating if product has a microphone |
| Over Ear | Binary field indicating if product is over-ear |
| Foldable | Binary field indicating if product is foldable |
Summary
In Part 1 of the Sound Decisions series, I discussed what web scraping is, its relevance and how to do it. I also covered how I processed the scraped data and carried out feature engineering to enhance the dataset.
In the next post, I will focus on exploratory data analysis (EDA) and gathering insights from the data.