Trick or ReTreat: An Introduction to Reinforcement Learning 🎃
Originally, I had another Halloween project in mind, Trick or Tweet. The aim was to perform sentiment analysis on Halloween themed tweets collected using X’s API. Unfortunately, due to the limits of a basic account, I was unable to search and retrieve tweets using the API. This led me to brainstorm a new Halloween themed project … Trick or ReTreat!

In this project, my goal is to develop a reinforcement learning model where a trick-or-treater must escape a haunted mansion, avoiding ghosts and collecting treats along the way. This is my first project using reinforcement learning and I’m excited to see where it takes me!
In Part 1 of this Halloween series, I will outline the details of the game and introduce key concepts of reinforcement learning.
Game Introduction
Welcome to the haunted mansion!
I’ve designed a 5x5 grid where each square is either empty or contains a piece of candy, a ghost, the exit door or the trick-or-treater.
The trick-or-treater can move in four directions: up, down, left and right and is limited to moving one square at a time. The game ends when they find the exit door of the haunted mansion.
The goal is for the trick-or-treater to find the optimal path to escape, collecting as many candies as they can while avoiding the ghosts haunting the mansion!
Visualisation

Key
🍬 Candy: Each candy the trick-or-treater collects earns a positive reward of 10 points.
👻 Ghost: Each ghost the trick-or-treater encounters results in a penalty of -10 points.
🚪 Exit Door: Success of exiting the mansion, the trick-or-treater receives the largest reward of 20 points.
🏃 Trick-or-Treater: Tasked with escaping the haunted mansion.
Reinforcement Learning
Let’s start with a simple example!
Imagine teaching a dog to sit. Each time the dog sits, it receives a treat as a reward. This positive feedback encourages the dog to repeat the same action again. When the dog doesn’t sit, it doesn’t get a treat. Over time, the dog learns that sitting earns rewards while not sitting doesn’t.
Reinforcement learning follows a similar process but in this case the reward is of numerical value.
Reinforcement learning models learn by trial and error, adjusting actions taken based on feedback given. Unlike other machine learning models, these models explore, make mistakes and get better at making decisions over time. Just like in real-life learning, it’s all about experience!
What is Reinforcement Learning?
Reinforcement Learning (RL) is a type of machine learning where a model learns through interactions and feedback. Instead of being explicitly told which actions to take, the model explores different actions to find ones which get the highest rewards.
Unlike supervised learning, where models generalise patterns from the labelled training data, RL does not rely on labels to make decisions. Instead, it focuses on evaluating the outcomes of actions taken by the model and uses this feedback to learn.
While RL does share some similarities to unsupervised learning, like the absence of labels, RL still differs in its approach. In unsupervised learning, the model identifies patterns and groups the data without any feedback on whether those groupings are correct. RL does not do this, RL uses feedback to improve decision making. This makes RL unique to both supervised and unsupervised learning.
Key Terms
-
AGENT: The actor that takes actions based on what it observes in the environment.
-
ENVIRONMENT: Describes everything the agent interacts with.
-
ACTION: The choices made by the agent that affect the environment. There is usually a predefined set of actions the agent can take.
-
STATE: Represents the current situation of the environment.
-
REWARD: A numerical value the agent receives after taking an action, can be positive (reward) or negative (penalty).
-
POLICY: The strategy the agent uses to determine which action to take based on the current state.
-
EPISODE: A sequence of actions starting from the initial state and continuing until the agent reaches the final state where the agent completes the scenario goal.
How RL works
As stated earlier, the objective of a RL model is to maximise the reward through trial and error. Below is a simple explanation as to how it does this. In the coming posts, I will go into more detail about how I created the RL model for my project.
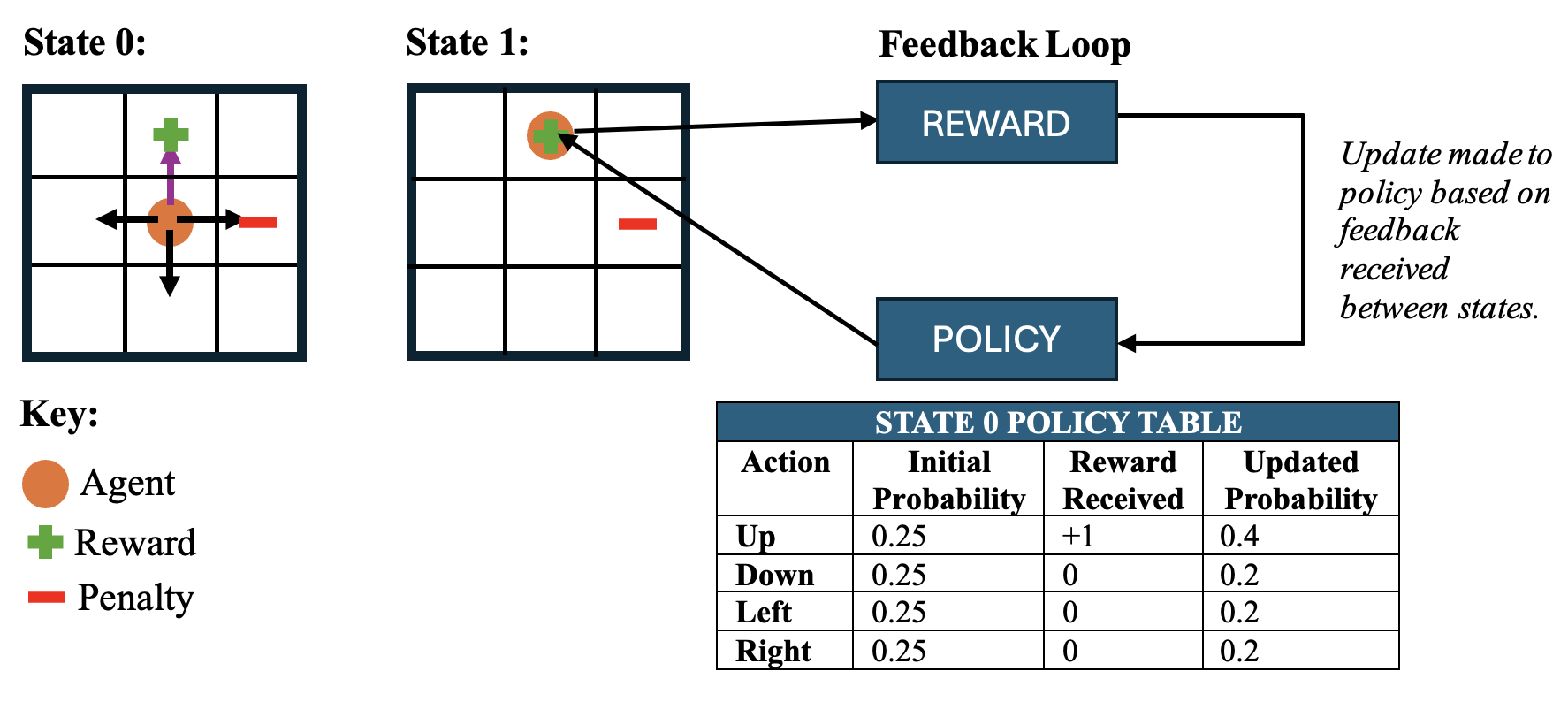
Step 1: Initialisation
The agent begins without knowing anything about the environment. In this step, the agent chooses an action randomly as shown by the purple arrow in State 0. This randomness helps the agent explore.
Step 2: Interaction
After taking an action, the environment moves to a new state (State 1) and in this example, the agent lands on a reward. This interaction is part of the exploration process and helps the agent learn which actions are better in a given state.
Step 3: Feedback and Policy Update
For each state, the agent evaluates the reward received and updates its policy. As seen in the table, after moving “up” and getting a reward in State 0, the probability of choosing the “up” action in State 0 increases from 0.25 to 0.40. The update to probabilities shows the agent is now starting to focus on actions that have given higher rewards, here we say the agent is exploiting its previous actions.
Note: This update is specific to State 0. If the agent moves to State 1, the probabilities of actions will be different. Any rewards from actions taken there will result in an update to State 1’s policy.
Step 4: Repeat Process
The agent continues to take actions in different states. Over time, it updates its policy based on the rewards it receives, balancing the exploration of new actions with the exploitation of known high-reward actions. To find the most rewarding actions, the agent must balance this exploration exploitation trade-off.
Exploration vs. Exploitation
Initially, the agent explores a lot to gather knowledge about the different states of the environment and their rewards. The exploration is needed to better understand the environment and to find the rewarding actions. However, as the agent learns more, it must start to exploit the best actions it has found. Finding the right balance between these two is important. The agent should take advantage of known high-reward actions, but it should also occasionally explore to ensure it doesn’t miss out on better opportunities.
To maintain the balance between exploration and exploitation, strategies like epsilon decay are used. Epsilon decay starts with a high epsilon value, which represents the exploration rate, allowing the agent to explore its environment. Over time, the epsilon value gradually decreases, encouraging the agent to focus more on exploiting actions that received high rewards in the past. This transition from exploration to exploitation helps the agent optimise its decisions while still leaving opportunity to explore new actions.
Action-Value Methods
In the diagram above, I have shown what a policy update looks like. After the agent takes an action, it adjusts the chances of selecting that action in the future depending on the reward received.
To calculate the probabilities in a policy table, the expected reward for each action in a given state is needed. The expected future reward is known as the action value. It estimates how good an action is in terms of receiving rewards and gives the agent a sense of how effective that action is overall.
How do we calculate action values?
In this post, I will focus on two primary methods used for calculating action values:
1. Sample Average Method
This is the simplest method used in cases where the environment is not too complex. In this approach, the agent waits until an episode is complete before updating its estimates.
\[\text{Expected Estimate for Action A} = \frac{\text{Total Reward for Action A}}{\text{Number of Times Action A was Taken}}\]In other words, this method averages all past rewards for action A.
2. Temporal Difference (TD) Learning
This is a more advanced method. Unlike the Sample Average Method, which waits until the end of an episode to update estimates, TD Learning allows the agent to update its policy after each action. This means that the agent learns in real-time.
TD Learning works by calculating the estimated rewards of actions based on the difference between predicted rewards and actual rewards. This approach helps the agent refine its action values step by step.
Two well-known methods that use TD Learning are Q-learning and SARSA. These methods will be explored in more detail in part 2 of the series.
While I have focused on these two methods for now, it’s important to note that there are other methods for calculating action values in reinforcement learning, such as Monte Carlo methods and Deep Q-Networks (DQN).
Action Selection
With the action values calculated, the next step is to use them to choose the best action. In this section, I will explore the two categories of action selection methods:
1. Greedy Action Selection
In greedy algorithms, the agent always chooses the action with the highest estimated action value. These methods aim to maximise immediate rewards but do not explore potentially better actions. While this can lead to quick rewards, it may also result in the agent missing out on more rewarding actions that haven’t been found yet.
2. Epsilon-Greedy Action Selection
This method strikes a better balance between exploration and exploitation. The agent mostly chooses the action with the highest estimated reward (exploitation) but occasionally picks a random action (exploration) to explore new possibilities. The probability of choosing a random action is controlled by a small value called epsilon. As discussed earlier, epsilon decay is a strategy that falls under this category.
Limitations
Despite the progressive approach of RL, it has its limitations.
Most of RL models assume a deterministic environment where the future states depend on the current state. However, this isn’t always true in real-life where random events occur. In my project, this limitation isn’t much of an issue since I’m working in a simulated environment.
Another challenge is that training RL agents can take a long time, especially in complex environments. The more there is to explore and exploit, the longer it takes for the agent to learn optimal actions. Finding the right balance between exploration and exploitation is needed but can be tricky to find.
Application to Trick or ReTreat
Let’s see how the above information can be applied to my project:
-
AGENT: Our trick-or-treater, who is learning how to escape the haunted mansion.
-
ENVIRONMENT: The 5x5 grid of the mansion where each square contains either a candy, a ghost, an exit door or is empty.
-
ACTION: The trick-or-treater is limited to four directions: up, down, left or right, moving one square at a time.
-
STATE: Current position of trick-or-treater on the grid, in this case it would be grid coordinates.
-
REWARD: When the trick-or-treater moves to a square with a candy, they earn 10 points as a reward. If they step into a ghost’s square, they lose 10 points as a penalty. Reaching the exit door is the ultimate goal and so earns a larger reward of 20 points.
Learning Process
Initial State:
The trick-or-treater starts at a random position on the 5x5 grid.
Action Selection:
Initially, the trick-or-treater randomly chooses to move up, down, left or right (let’s call this action A).
Feedback:
After moving, the trick-or-treater receives feedback based on the square they land on; if they find candy they earn 10 points, if they find a ghost they lose 10 points.
Policy Update:
Based on the feedback, the trick-or-treater updates its policy. If the reward for action A is positive, it increases the likelihood of selecting that action again in similar situations. The action-value estimate for action A is updated.
Repeating the Process:
Over time, the trick-or-treater collects data from its actions and uses feedback to better understand the environment. It learns to identify and favour actions that maximise rewards. This allows the trick-or-treater to optimise its path to escape while collecting as many candies as possible.
Summary
In this post, I introduced my latest project Trick or ReTreat. I discussed the basics of Reinforcement Learning, highlighting its differing approach to traditional machine learning methods.
As we progress to building the RL model in Part 2, I’ll dive deeper into the details of reinforcement learning.