Trick or ReTreat: Implementing Reinforcement Learning 👻
So far, I have introduced the basic concepts of Reinforcement Learning (RL) and outlined the environment and rules for my RL project, Trick or ReTreat.
In this post, I’ll explore two key libraries in RL: OpenAI’s Gym and Stable Baselines3, both of which streamline the process of building and training RL agents. Using the Lunar Lander environment, I’ll showcase two demos: one showing an agent taking random actions and another after training the agent.
OpenAI’s Gym
In this project, I will use OpenAI’s Gymnasium library (a branch of the original Gym library) to build and train my reinforcement learning agent for Trick or ReTreat. It is a common library to use in reinforcement learning.
To get familiar with Gymnasium, I began by experimenting with its pre-defined environments. This approach helped me gain a solid understanding before diving into creating a custom environment for Trick or ReTreat. To start, I’ll give a brief introduction to Gymnasium, summarising its key features and functions based on its documentation.
Environments
Thinking back to the previous post, an environment represents everything an agent interacts with. This includes the various states, the actions the agent can take and the placement of rewards. Let’s see how we can represent this in OpenAI’s Gymnasium.
Initialising Environments
Using pre-defined environments from Gymnasium is fairly straightforward - simply call make() function to initialise an environment.
Interacting with the Environment
In Gymnasium, environments are represented as classes. Below is an overview of key functions for interacting with these environments
1. reset()
-
Resets environment to its initial state.
-
Must be called before running
step()to start a new episode. -
Initial state of environments usually have randomness to ensure exploring, the randomness can be controlled by the
seedparameter.
2. step()
-
Input: The action A that the agent takes.
-
Returns the following:
-
New State (called observation): Environment’s new state after taking action A.
-
Reward: The reward received for taking action A.
-
Terminated: A Boolean indicating whether the agent has reached a goal or completed the task
-
Truncated: A Boolean that is True if the episode ends due to step limits or other specified conditions.
-
Info: A dictionary of additional information, useful for debugging or analysis.
-
3. render()
-
To help visualise what the agent observes in the environment.
-
render_modeis commonly set to:-
rgb_array: Returns an image of the environment as an array of shape (x, y, 3). -
human: Displays environment for real time.
-
4. close()
-
Used to clean up and close the environment after use.
-
This includes closing all rendering windows.
Spaces
Spaces define the format of actions and observations. They describe the types of actions the agent can perform and the types of observations the agent can receive from the environment.
Each environment must have the following two types of spaces defined:
1. action_space: Represents all the possible actions an agent can take.
2. observation_space: Represents all possible states that the environment can return to the agent.
Each of these spaces must be defined with a type.
Different Types of Spaces
The main types of spaces are:
1. Box:
-
Used for continuous values within a specified range.
-
Example for Actions: An agent can move within an angle range of 0 to 180 degrees.
-
Example for Observations: A temperature sensor that measures temperatures between 30 and 40 degrees
2. Discrete:
-
Represents a finite set of actions or states.
-
Example for Actions: An agent can move in only four directions: up, down, left and right.
-
Example for Observations: A game board with two possible states: empty or containing a reward.
3. MultiBinary:
-
Represents binary values, often used for switches or sensors that are on/off.
-
Example for Actions: Buttons on a controller, pressed or not pressed.
-
Example for Observations: A light sensor that returns 1 if activated and 0 if not.
These are the basic spaces but there are others for more complex environments.
Stable Baselines3
After watching many tutorials, I noticed that a lot of people use the Stable Baselines3 library.
Stable Baselines3 is a library for RL, specifically designed to work with OpenAI Gym environments. It simplifies the process of setting up, training and evaluating RL agents. In the example below, I’ll share my first attempt at using RL with Stable Baselines3.
Wrappers
Wrappers are templates used to modify the functionality of environments without changing the original environment setup. For instance, if you want to change rewards or reshape some observations, you can do this using a wrapper instead of having to re-create the environment.
There are various types of wrappers depending on the specific changes or functionalities you need from the environment.
While you can use wrappers directly from Gymnasium, the wrappers in Stable Baselines3 are simpler and more effective. They are designed to enhance the training process of RL agents.
Vectorised Environments
One of the most commonly used wrappers in Stable Baselines3 is the vectorised environment wrapper. These wrappers allow you to manage multiple instances of an environment at the same time. It allows the agent to interact on multiple states of the environment simultaneously leading to faster training and greater diversity in the agent’s experiences.
In the demo below, I used DummyVecEnv to run four instances of the Lunar Lander environment.
Lunar Lander
The Lunar Lander environment is a classic control reinforcement learning task where an agent must successfully land on a landing pad while managing its speed, angle and engine thrust.
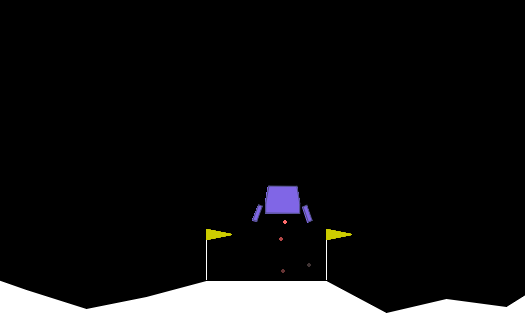
Below is an overview of agent’s action space, observation space, rewards and episode end conditions.
Action Space
The agent can take any of the following four discrete actions:
-
0: Do nothing
-
1: Fire the left engine
-
2: Fire the main engine
-
3: Fire the right engine
Observation Space
The observation space is defined as a box with the following bounds:
-
Lower Bound: [-2.5, -2.5, -10, -10, -6.2831855, -10, 0, 0]
-
Upper Bound: [2.5, 2.5, 10, 10, 6.2831855, 10, 1, 1]
-
Shape: 8-dimensional vector
The observation vector contains the following elements:
1. X Position: Horizontal position of the lander.
2. Y Position: Vertical position of the lander.
3. X Velocity: Velocity of the lander along the x-axis.
4. Y Velocity: Velocity of the lander along the y-axis.
5. Angle of Lander: The current angle of the lander.
6. Angular Velocity: The rotation speed of the lander.
7. Left Leg Contact: 1 if the left leg is in contact with the ground, 0 if not.
8. Right Leg Contact: 1 if the right leg is in contact with the ground, 0 if not.
Reward Structure
The goal of the agent is to land between the two flags. Rewards are given based on the following criteria:
-
The closer the lander is to the landing pad, the more points are awarded.
-
Points are also awarded for reducing the lander’s speed.
-
The reward decreases if the lander is more tilted.
-
Each leg in contact with the ground awards an additional 10 points.
-
Firing the side engines incurs a penalty of -0.03 points each time (indicated by red dots in the rendering).
-
Firing the main engine incurs a larger penalty of -0.3 points each time.
-
An additional reward of +100 points is given for a safe landing, while crashing results in a penalty of -100 points.
-
A reward above 200 points indicates good landing and performance of the agent.
Episode End Conditions
An episode can end in two ways:
-
Truncation: The episode is truncated when the agent scores 200 points.
-
Termination: The episode terminates if the lander crashes, goes out of bounds or becomes asleep.
Random Action Selection
To start, I explored the effects of the agent randomly selecting actions from its action space to see how the agent performs. This helped me familiarise myself with using basic concepts of both libraries. I limited the number of steps to 1000 to avoid lengthy runtimes.
Code Snippets
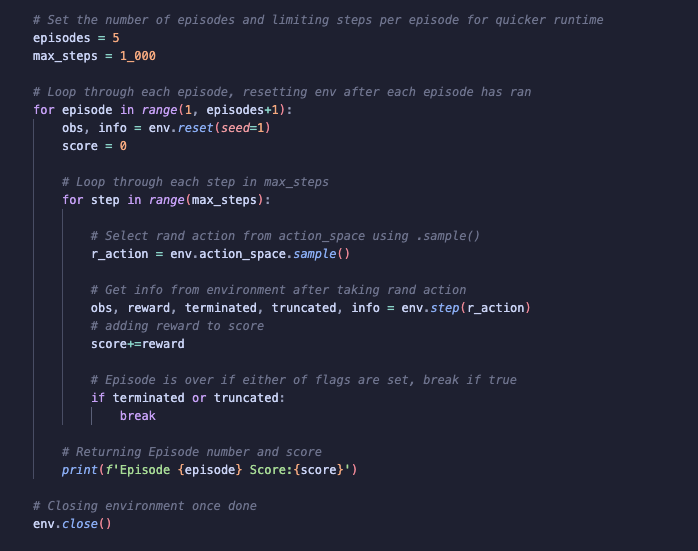
Setting up Lunar Lander Environment using gym.make(), setting render_mode as human to get visual output.

Testing the agent with random actions, I am using max_steps and episode parameters to control run time. Since using random action selection, the agent may take a long time to complete the task.
Results
I collected the total rewards per episode (capped at 1000), below are the results:
| Episode | Score |
|---|---|
| 1 | -238.99 |
| 2 | -151.35 |
| 3 | -293.43 |
| 4 | -498.66 |
| 5 | -94.48 |
It’s clear that the performance was poor, as all scores are negative. The agent fails to achieve the task through random actions, highlighting the need for training to better understand its environment.
Visualisation
Actions taken by the agent show no purpose, the agent struggles to control itself as it travels down towards the ground.
Proximal Policy Optimisation Algorithm
After exploring the Lunar Lander environment through random action selection, I wanted to improve the agent’s performance through training.
Stable Baselines3 documentation is very thorough and provides a list of all available RL algorithms for training. In the end, I chose Proximal Policy Optimisation (PPO) because it is relatively simple to understand and quite stable.
What is PPO?
PPO is a policy-based algorithm meaning it learns a policy by optimising probability of taking high rewarding actions. PPO makes gradual, controlled updates to the policy, so the agent doesn’t make drastic changes all at once.
After the first episode, the agent builds a policy based on its observations of the environment. In the following episodes, the agent continues to collect observations while recording the rewards associated with each action taken. PPO calculates the reward for each action and compares it to the expected outcome (previous episode results). Using these comparisons, PPO updates the action probabilities to increase the likelihood of taking actions that receive higher rewards. If the difference between the old and new action probabilities is too drastic, PPO uses ‘clipping’ to ensure stable learning.
Code Snippets
Before I train the agent, I first vectorise the environment to create four parallel instances of the environment. This allows faster training as the agent can explore multiple states at the same time. I decided not to render the training environment to avoid the added computational cost as visual inspection of training isn’t really needed.

I set the log path to better understand the training metrics in TensorBoard later.
I then initialised my model with PPO using the MLP policy (default policy). MLP policy is a simple neural network structure of fully connected layers, it takes in environment observations and outputs actions. Essentially, this policy performs updates using a neural network to help the agent ‘learn’. There are other policies that can be used, but for this demo MLP policy seemed the best choice since the Lunar Lander environment isn’t too complex.


After instantiating the model, I train the agent setting the total_timestep to a million. Lunar Lander agent has several actions to try out, so I thought a high timestep gives the agent enough opportunity to explore the environment well.

To evaluate the model’s performance, I use evaluate_policy. This is a Stable Baselines3 function which returns a tuple, average reward and standard deviation of rewards across a given number of episodes.

The results show the agent achieves a strong average reward of 249 across 10 episodes, indicating the success at learning and completing the task. Standard deviation of 34 suggests some variability in the episode scores, ideally the standard deviation should be a bit lower to show more consistency in the agent’s performance.
Testing Results
After training the model, I tested its performance over 10 episodes. Here are the results:
| Episode | Score |
|---|---|
| 1 | 17.01 |
| 2 | 262.80 |
| 3 | -28.20 |
| 4 | 266.47 |
| 5 | 293.32 |
| 6 | 242.91 |
| 7 | 278.50 |
| 8 | 250.77 |
| 9 | 241.46 |
| 10 | 280.66 |
Overall, agent shows a much stronger performance with most scores above 200. There are some low and even negative scores which may suggest the agent struggled in certain scenarios.
Visualisation
Clear improvement in the agent’s performance after training.
Summary
So far, I have covered the basics of reinforcement learning and demonstrated how to train agents using OpenAI’s Gymnasium and Stable Baselines3, applying the PPO algorithm in the Lunar Lander environment. While PPO worked well overall, there were a few cases where the agent’s performance was inconsistent, with some episodes scoring lower than expected.
Next, comes the real challenge! I will be applying what I have learnt so far to set up my own custom environment for Trick or ReTreat and attempt to train an agent using Q-learning!