Email Genie: Data Loading and Cleaning 🧹

Whenever I open my email, the number of emails I receive in a single day can be overwhelming. I started thinking: what if there was a way to better classify emails based on their content? This could be useful, especially in the corporate world, where managing large volumes of emails is a daily task for many. I decided to use my data science skills to build a classifier tailored to day-to-day business tasks. While I understand the challenges of working with unstructured data like text, I’m excited to give it a go!
For this project, I’m using the Enron dataset. This project will be completed in the following phases:
Phase 1: Data Preprocessing and Insights
In this phase, I will clean the emails as best I can and prepare the data for modelling. I will also provide initial insights into the content of the emails.
Phase 2: Clustering
This phase will involve grouping similar emails together based on their content using unsupervised learning. The goal is to identify patterns or themes within the emails, which could help in classification.
Phase 3: Modelling
Build and train a classifier that can categorise emails based on their content. I’ll experiment with different models to determine the most effective model.
In this blog post, I’ll walk through part of the first phase, covering data loading and data cleaning.
Data Loading
I sourced the dataset from Kaggle, where the emails were stored in a CSV file, with each email wrapped in a some sort of wrapper. I assume this is as the emails are in raw form, extracted from an email server. For my project, I needed to extract the following fields:
-
To
-
From
-
Subject
-
Body
Initially, I attempted to use regular expressions to extract the data. However, I quickly realised that this approach wasn’t ideal. Emails are not standardised and do not follow a consistent format. For example, some emails contain multiple recipients and delimiters separating recipients are not consistent. I have kept my attempt at extracting data using regex in the appendix of the Data Cleaning notebook.
After some research, I came across an article about the EmailParser library, which seemed to deal with the complexities of email data. This library is specifically designed for parsing email data, even when it comes from raw email servers. Below is a screenshot with how I used this library to successfully extract the necessary data from the csv file.
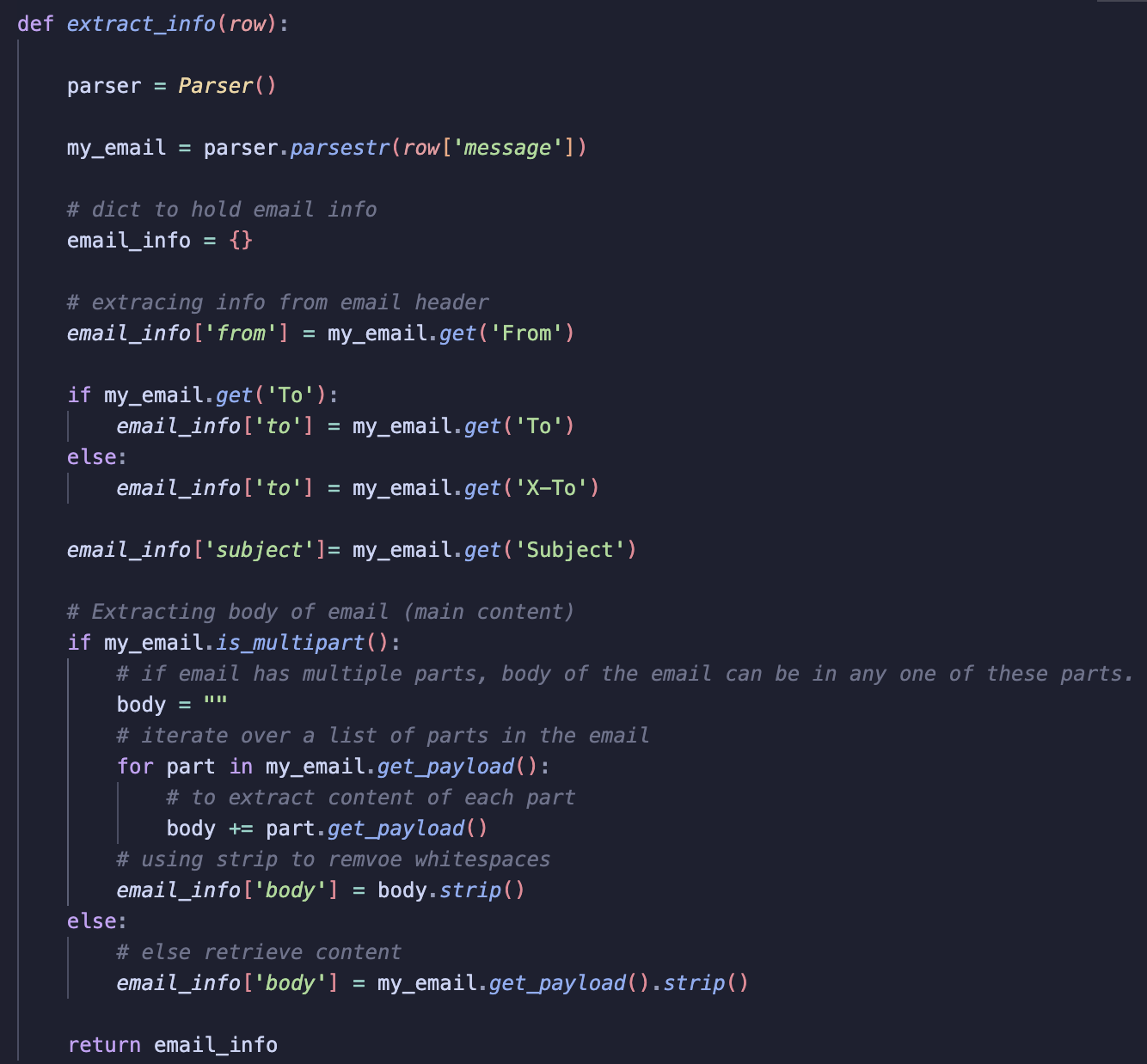
Let’s walk through the function part by part:
1. Instantiating the Parser class using Parser()

Creates an instance of the Parser class from EmailParser library. Once instantiated, it allows access to all the methods available for parsing emails and extracting data.
2. Create Message Object from Data using .parsestr()

Takes a string as input and converts the string to a Message object. I iterate over each row in the dataset transforming each email to a Message object.
3. Create a Dict to Store Extracted Data

All extracted email data is stored in this dictionary. At the end of the function, this dictionary is returned.
4. Extract Information from Email Headers using get()
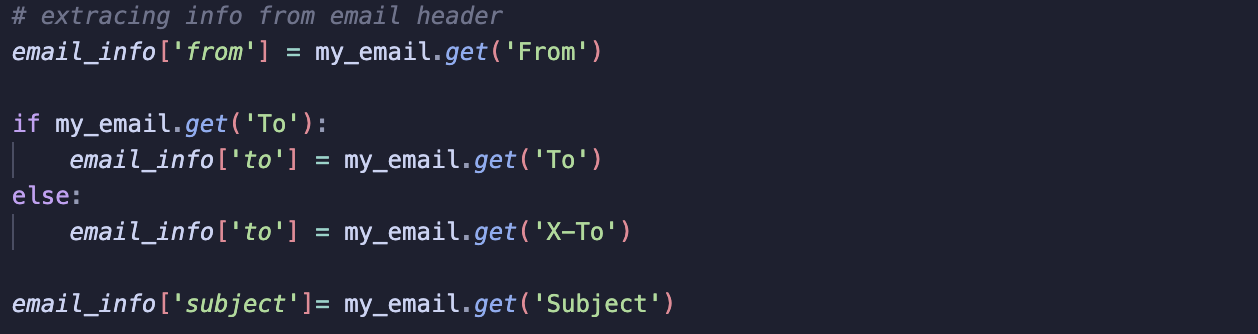
Retrieves values of specific fields from email headers like to, from, and subject. In some cases, certain headers (like To) were missing, so I included logic to check for alternate fields (e.g., X-To).
5. Extract Body of Emails Using is_multipart()
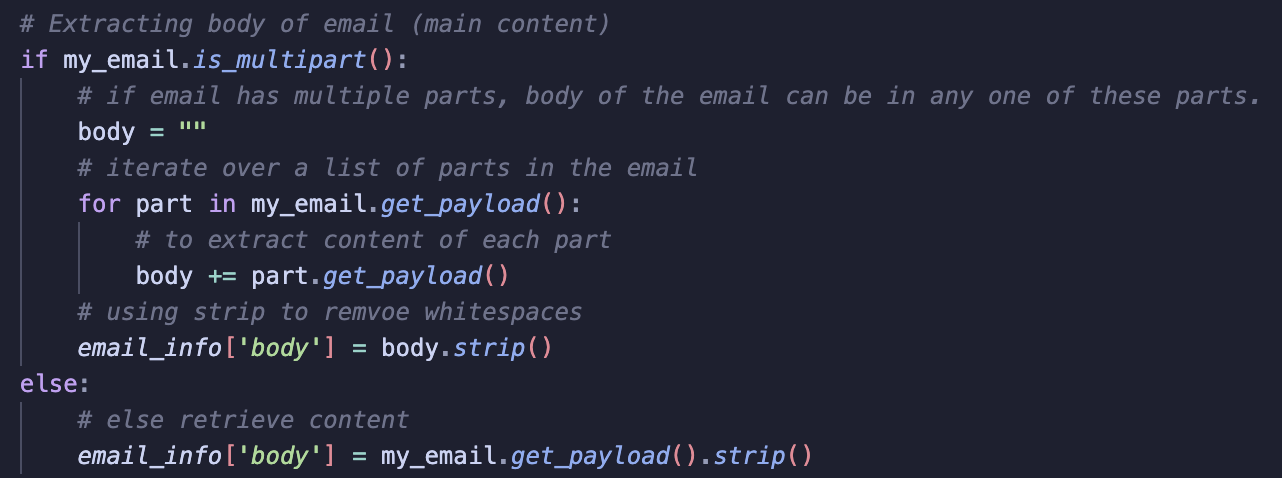
Here, I check if an email is multipart, meaning it contains multiple parts such as plain text and attachments. If it is, I loop over each part to concatenate all email parts together.
To extract content, I use get_payload(). I also call .strip() to remove any leading or trailing spaces.
For this project, I decided to ignore attachments and focus only on the body content. The reason for this is that attachments can be hard to process due to varying file types.
With all the required data extracted from the CSV, I focused my attention to cleaning the data.
Data Cleaning
As with any data project, ensuring that the data is clean is the most important step before diving into analysis or applying machine learning models. Text data is no exception - it must be properly cleaned before any processing can take place. In the section below, I’ve broken down the stages I followed to clean the data.
Note: Since the dataset is rather large, I have kept my analysis to 50,000 emails - if necessary, I can increase this at a later stage.
Standard Cleaning Steps
To begin, I first removed any rows with null values. This was important because, in order to successfully group, cluster, or classify emails, I thought it best to have a complete dataset. Having missing data could affect the performance of the models and lead to inaccurate results.


After addressing the null values, I addressed duplicated rows by dropping them. Duplicates not only add redundancy but could also confuse the model, potentially introducing bias and affecting the quality of insights generated.

After dropping rows, I reset the index to ensure index is continuous.

Email Cleaning Steps
With the dataset now free of null values and duplicates, the next step was to focus on the email content itself. This is where the real data cleaning took place—removing noise such as email headers, HTML tags, links, punctuation, and unnecessary newline or tab characters.
This process turned out to be more iterative than I initially expected. As I progressed to vectorising the data to generate insights, I continuously updated my cleaning function.
Below is the full cleaning function I developed:
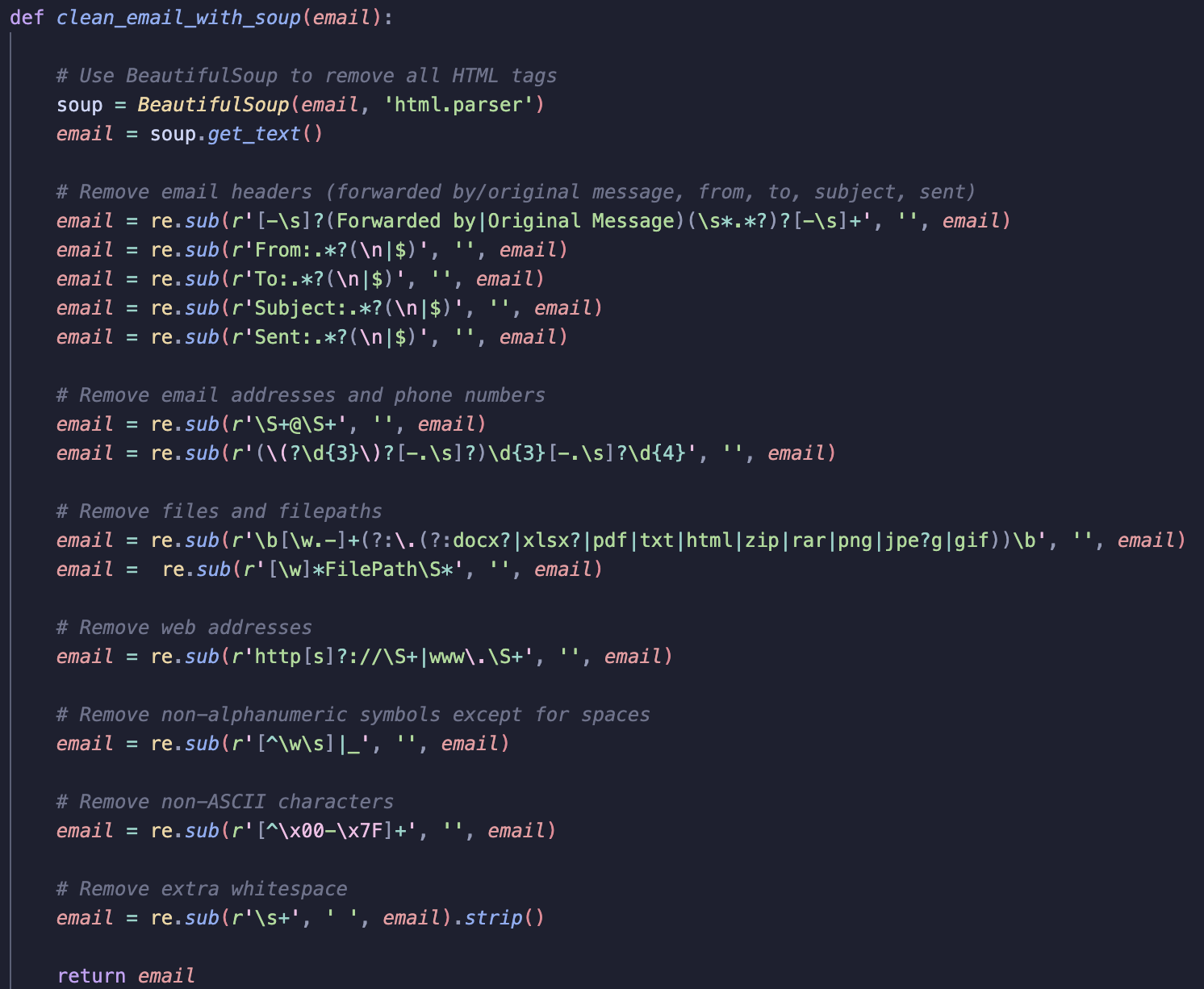
Let’s break down the cleaning function to understand which parts of the code addresses what noise.
Removing HTML Tags
At first, I didn’t expect HTML tags to be a significant issue in my data. However, when I vectorised the text on, I was surprised to find a high volume of HTML tags among the top tokens and so had to revisit data cleaning to remove them. To do this, I used BeautifulSoup.

After instantiating BeautifulSoup, I used the .get_text() method to extract all the visible text from inside the HTML tags, stripping away any HTML elements.
Removing Email Headers
I used regular expressions to remove common email headers like “Forwarded By”, “Original Message”, “To” and, “From”.
I used re.sub() to find these headers and replace them with an empty string. Here’s what each regex pattern does:

Matches lines that contain “Forwarded by” or “Original Message” and removes them, along with any extra whitespaces and hypens.

Matches the “From:” header and removes the line starting with it.

Similar to the “From:” header, it removes the “To:” header.

Removes the “Subject:” line.

Removes the “Sent:” line and any other info like date/time the email was sent.
Removing Email Addresses and Phone Numbers

Email addresses: The regex \S+@\S+ matches any text which has no whitespace and @ symbol. There were many email addresses in varying formats, not all of which ended with typical domains like .com or .co.uk.

Phone numbers: The regex matches phone numbers in America like (123) 456-7890 or 123-456-7890, and removes them.
File Paths

The first re.sub() removes file names that include file extensions like .docx, .pdf, .zip.
The second removes file paths, like FilePath: C:\Users\Name\Documents\file.txt.
Removing URLs

This regex matches any URL starting with http://, https://, or www. and removes it from the text.
Removing Non-Alphanumeric Symbols, Non-ASCII Characters and Whitespaces

Removes any non-alphanumeric characters (anything other than letters, numbers, and spaces).

Removes any characters that are not part of the ASCII set.

Removes extra spaces, tabs, and newline characters.
In my cleaning function, I’ve worked to address all the types of noise I saw in the dataset. While I’m sure there are still some things I may have missed, I feel confident that I’ve removed enough of it to move on to generating valuable insights. Data cleaning, especially with text, can easily become an endless task, and I spent a considerable amount of time refining this function. I didn’t want to spend too long on this part of the project, knowing I can always revisit and make changes later if necessary.
Summary
In this post, I explained and showed how I extracted relevant email fields from the Enron dataset using the EmailParser library. I also shared the steps I took to clean the data, ensuring it was ready for analysis. This process involved removing unwanted noise, such as HTML tags, email headers, email addresses, phone numbers, file paths, and URLs, using regular expressions and the BeautifulSoup library.
In the next post, I’ll share the steps I took to vectorise the text data in preparation for using machine learning models, and I’ll explain the different methods I used.