Email Genie: Labelling 🏷️

In the last post of the Email Genie series, I used a pre-trained Sentence Transformer to create embeddings for Enron emails and evaluated their quality. The next step is to begin the classification phase. To do this, I needed to label my emails to create a ground truth for the classification models to learn from.
In this post, I’ll share the different categories I classified the emails into, explain how I completed the labelling process and share some things I did to speed it up. While accuracy in labelling was important, I wanted to avoid spending too long on it…
Labelling Emails
First, I needed to decide on some topics to categorise the emails into. Initially, I considered using more granular topics that are common across most businesses. However, conscious of not wanting to spend too long on this phase, I decided to restrict the categories to the following: Finance, Operations, Legal, Spam, and Personal. You may recognise that the first three topics were identified at the start of the project, and I thought this would be a good place to begin since I had already used them when evaluating the embeddings.
Category Descriptions
-
Finance: Emails covering financial matters such as invoice queries, stock and trade discussions, budgeting, quarterly reports and general financial reporting.
-
Operations: Emails about day-to-day activities, including mailing lists, meetings, reservations, recruitment, travel arrangements, resignations, internal announcements and visa-related queries.
-
Legal: Emails dealing with legal issues such as bankruptcy, contracts, compliance, litigation and other regulatory matters.
-
Spam: Advertising, phishing and scam messages
-
Personal: Informal conversations such as birthday wishes, casual chit-chat, sports, trip anecdotes, brown bag sessions and leaving or welcoming emails.
How many emails to email
Now that I had my categories finalised with clear definitions, I needed to decide how many emails would be needed in my training set for the classification model to perform well. Obviously, I didn’t want to sift through all the emails and label each one manually. So in the end, I decided to aim for around 200 emails per category. I thought this was a good number, not so many that labelling would take too long, but enough to give the model sufficient data to learn.
Note: I’m still not sure if this is enough, but the model’s results will help me decide if I need to increase this later.
Quick and Dirty Labelling
Even with restricting the categories to 200 emails each, that still left me with 1000 emails to label manually. A rather daunting and painstaking task that would take too long, especially with no guarantee my model would perform well.
So, I decided to use regular expressions to speed up the process. My idea was to create a set of regex patterns for each category, label the emails automatically where possible, and then review each email’s category to correct any mistakes. It was still a long process, but much faster than labelling everything from scratch! In hindsight, there are probably more accurate ways to help speed this process up but at the time this approach seemed the simplest.
Code Snippet
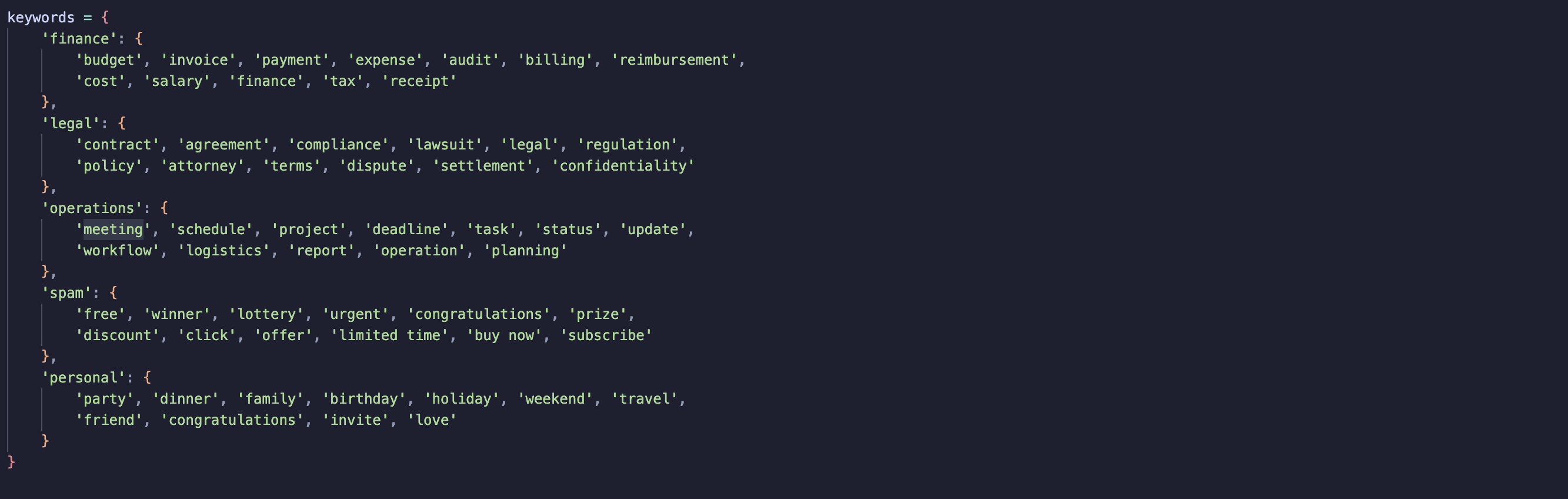
Step 1: Defining keywords for each category
To get started, I created a list of keywords for each category. These were based on the kinds of emails I had already seen, common terms like “invoice” or “budget” for Finance or “contract” and “litigation” for Legal.

Step 2: Label!
I then looped through the emails and searched for any of the keywords in the body text. If a word matched, the email was assigned the associated category. It probably wasn’t the most accurate approach, but it gave me a helpful starting point. From there, I used a PyWidges to scroll through each email alongside its label, so I could manually review and correct as needed. It was still a time-consuming task but much faster than doing it entirely from scratch.
Note: As you expect, many emails were classed under multiple categories. Even though this is likely in the real world, I decided to keep things simple and assign a single category to each email. I thought it best to keep things simple especially given the relatively small size of the dataset,
Recomputing Embeddings
The dataset now contains around 1,000 emails, split fairly evenly across five categories. This labelled dataset will serve as the training set for my classification models (which I’ll explore in the next post).
With the labelling complete, the next step was to recompute the embeddings using a pre-trained SentenceTransformer. Since classification models require numerical input, embeddings are the best way to represent text while retaining some semantic meaning (as discussed in earlier posts).
Summary
In this post, I shared through the process of preparing labelled data for my project. I started by defining my categories: Finance, Operations, Legal, Spam, and Personal and briefly described what each includes. To keep the task manageable, I aimed for 200 emails per category and used a combination of regex-based automation and manual review to speed up the labelling process.
Finally, I recomputed the SentenceTransformer embeddings for the labelled dataset, which will serve as input to the classification models in the next stage.