SimBot: Chatbots Explained 💡

Before diving into Phase 1 of SimBot, I thought it would be helpful to take a step back and explain what chatbots are, how they work and how they generate responses.
What is a Chatbot?
Simply put, a chatbot is a digital assistant made to communicate with users via text. A user sends a message (called a prompt) and the chatbot generates a response.
While this seems simple, chatbots can be built in very different ways depending on their purpose. Before looking at those differences, let’s understand how chatbots work at a high level.
How Chatbots Generate Responses
Nowadays, most chatbots are powered by large language models (LLMs). Rather than being programmed with rules, these models learn how language works by analysing large amounts of text during model training.
Once trained, the weights of the model are frozen and used to generate responses. When a user sends a prompt, the chatbot generates its response one token at a time.
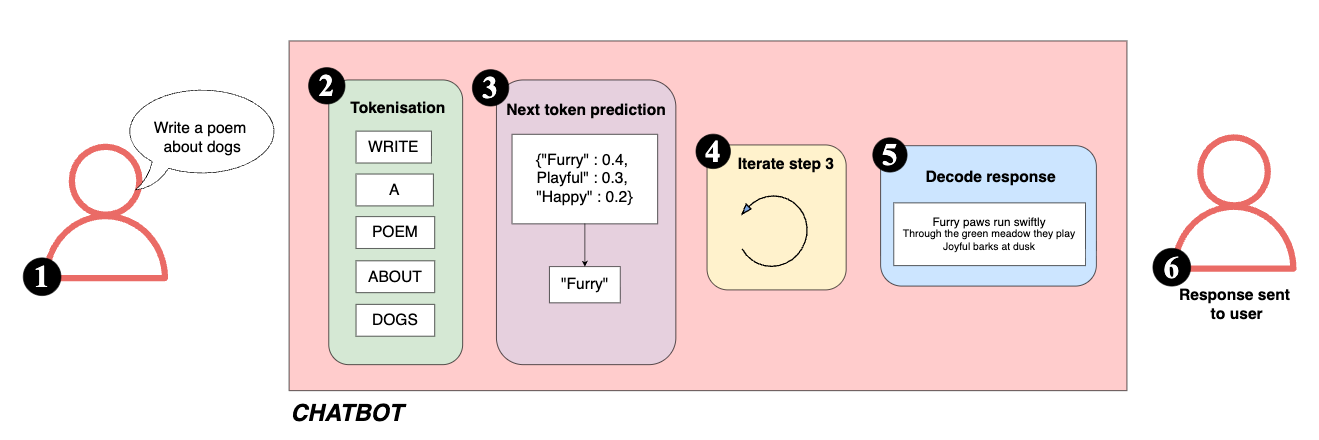
This process looks like:
-
The user sends a prompt to the chatbot.
-
The text is tokenised into smaller parts the model can process.
-
The model predicts the most likely next token based on the input and its training.
-
This process repeats until a full response is generated.
-
Tokens are decoded back into readable text.
-
A response is returned to the user.
These chatbots work really well for general conversation, but they do have limitations. Since the model is only generating text based on what it learnt during training, it cannot retrieve external information on its own. The use case of a chatbot influences how it is designed and built. To understand this better, let’s look at the different types of chatbots.
Types of Chatbots
The three most common types of chatbots are:
1. Rule-Based Chatbots: These are non-AI chatbots that use predefined rules to generate responses. They are limited to what has been programmed. For example, a customer service bot that only answers questions from a list of predefined categories, such as returns, store locations, exchanges, etc.
2. Generative AI Chatbots: These chatbots use AI models (LLMs) to generate responses by predicting the next word in a conversation. They can handle a wide range of topics and provide more human-like interactions.
3. RAG (Retrieval-Augmented Generation) Chatbots: These chatbots combine generative AI with access to external knowledge bases. By retrieving relevant information and using it to generate responses, they can provide more accurate answers.
How RAG Chatbots Work
Instead of relying only on what the model learned during training, a RAG chatbot first retrieves relevant information and uses it as added context when generating a response. The process of generating responses is a little different:
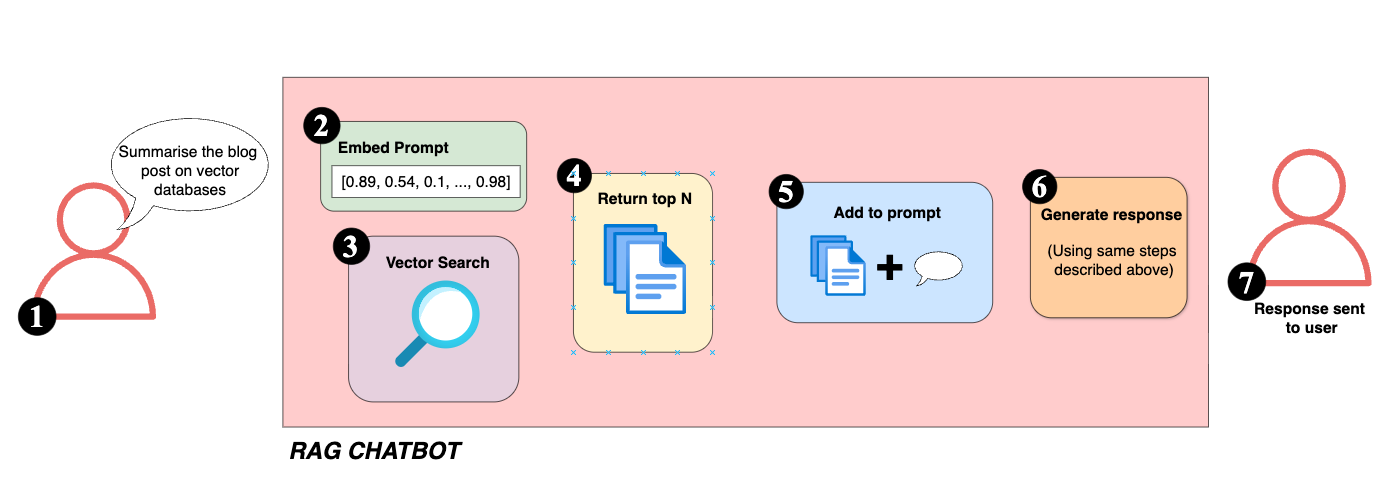
-
A user sends a prompt to the chatbot.
-
The prompt is preprocessed and embedded.
-
Embedded prompt is used to search a vectorised knowledge base (for example, blog posts or documents).
NOTE: All text in knowledge base is vectorised prior to retriveal. Embeddings for the knowledge base are created during the implementation of the RAG chatbot. The same embedding model is used to vectorise both knowledge base content and user prompts, this is done to ensure consistency for similarity matching.
-
Most relevant snippets or documents are returned.
-
Retrieved snippets are added to the prompt.
-
A response is generated (following steps above).
-
A response is returned to the user.
This approach allows the chatbot to answer questions about specific or private content. As part of this series I will share implementation steps to build my own RAG chatbot (SimBot) using previous blog posts.
Summary
I hope this overview helped you better understand chatbots and how they generate responses! In the next post, I’ll share findings from the first phase of the project, where I experiment with simple generative chatbots and explore how they respond to different prompts.